News
- Apr 10, 2026: 1 paper accepted to CVPR'26 Efficient Deep Learning for CV Workshop.
- Mar 17, 2026: 1 first-authored paper on AI for precision healthcare accepted to Nature Scientific Reports.
- Feb 11, 2026: I defended my PhD dissertation! Many thanks to my great advisors Prof. Shu Kong
and Prof. James Caverlee!
- Dec 8, 2025: I passed my PhD preliminary exam. I got my PhD candidacy ;)
- Aug 20, 2025: 1 paper accepted to EMNLP Findings 2025.
- Jul 29, 2025: our work ERIC was featured by Texas A&M Engineering News and ASEE First Bell's Newsletter.
- Jun 11, 2025: I am co-hosting the 5th Open World Vision Workshop at CVPR'25 in Nashville, TN. Let's meet!
- May 27, 2025: our paper SWAT is accepted to both FGVC12 workshop and CVinW workshop at CVPR'25.
- May 19, 2025: I am excited to start my internship at VISA Research working on Agentic LLM.
- Apr 29, 2025: our extended journal submission of ERIC was accepted to ACM Transactions on Sensor Networks.
- Apr 1, 2025: I was awarded TAMU CSE department travel grant.
- Feb 26, 2025: our paper SWAT is accepted to CVPR'25 ;)
- Nov 7, 2024: our paper ERIC has won ACM BuildSys'24
Best paper award !!!
- Oct 2024: 1 paper on adapting foundation models for video understanding was accepted to WACV'25.
- Sep 2024: 1 paper on building efficient computer vision system was accepted to ACM BuildSys'24
as Best paper candidate!
- Jun 2024: Coordinated the 4th Open World Vision Workshop at CVPR'24, Seattle.
- Jun 2024: Our paper "The Neglected Tails in Vision-Language Models" was accepted to ICML 2024 DMLR Oral.
- Mar 2024: I was awarded TAMU CSE department travel grant.
- Mar 2024: I received TAMU CSE Graduate Teaching Assistant Excellence Award (1 each year).
- Mar 2024: I passed Ph.D. qualify exam with 99% percentile.
- Feb 2024: 1 paper on improving VLMs for zero-shot recognition was accepted to CVPR'24.
Research
My research focuses on few-shot recognition with pretrained foundation models, especially Vision-Language Models (VLMs),
for solving challenging fine-grained recognition tasks,
such as recognizing the biological species from image data.
The core challenge in limited labeled data motivates my prior works in retrieving open data and
exploiting unlabeled data to boost few-shot
recognition performance.
In addition, I have broad interest in cyber-physical systems, building efficient multimodal systems for IoT and edge devices,
as well as AI for Science that leverages machine learning to solve crucial healthcare and geoscience problems.
Vision-Language Models
|
Surely Large Multimodal Models (Don’t) Excel in Visual Species Recognition?
Tian Liu*, Anwesha Basu*, James Caverlee, Shu Kong
arxiv /
website /
code
We find LMMs struggle in VSR, yet they can significantly boost few-shot recognition performance through post-hoc correction.
|
|
Solving Semi-Supervised Few-Shot Learning from an Auto-Annotation Perspective
Tian Liu, Anwesha Basu, James Caverlee, Shu Kong
arxiv /
website /
code
We reveal the root cause of failures in semi-supervied finetuning a VLM and propose simple temperature tuning remedies.
|
|
Enabling Validation for Robust Few-Shot Recognition
Hanxin Wang*, Tian Liu* (*co-first authors), Shu Kong
arxiv /
website /
code
We repurpose retrieved open data for validation, enabling realistic hyperparameter tuning
and model selection for robust few-shot adaptation of VLMs.
|
|
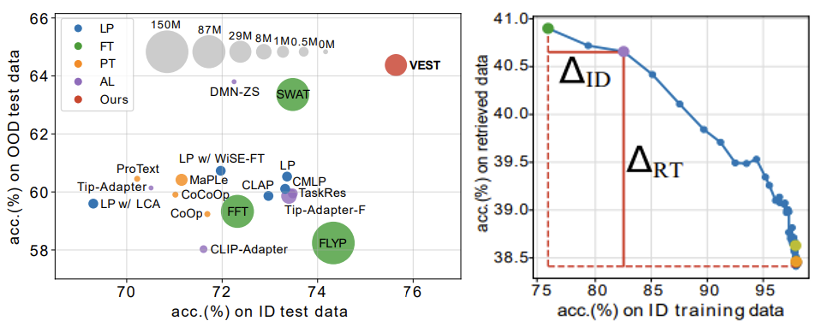
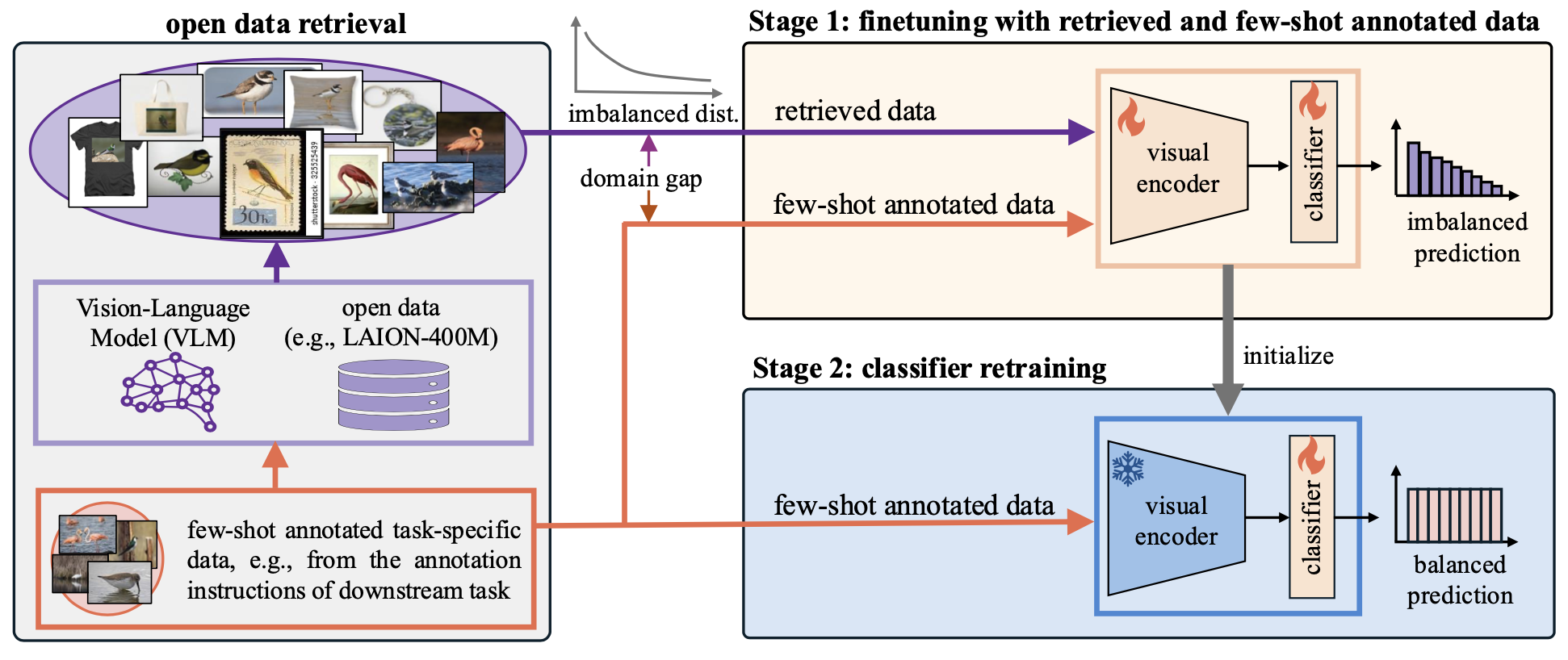
Few-Shot Recognition via Stage-Wise Retrieval-Augmented Finetuning
Tian Liu, Huixin Zhang, Shubham Parashar, Shu Kong
[CVPR 2025, 4th CVinW and FGVC12 workshops]
arxiv /
website /
poster /
code
We retrieve open data for solving few-shot recognition,
and propose stage-wise training to mitigate the imbalanced distribution and domain gap issues.
|
|
|
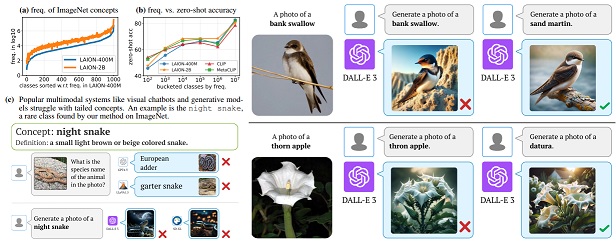
The Neglected Tails in Vision-Language Models
Shubham Parashar*, Zhiqiu Lin*, Tian Liu* (*co-first authors), Xiangjue Dong,
Yanan Li, Deva Ramanan, James Caverlee, Shu Kong
[CVPR 2024, ICML 2024 DMLR Workshop Oral]
paper /
DMLR /
arxiv /
website /
poster /
code
We expose the long-tailed concept distributions in VLMs' pretraining data
and reveal failues of SOTA multimodal systems (e.g. GPT-4V, DALL-E 3).
|
|
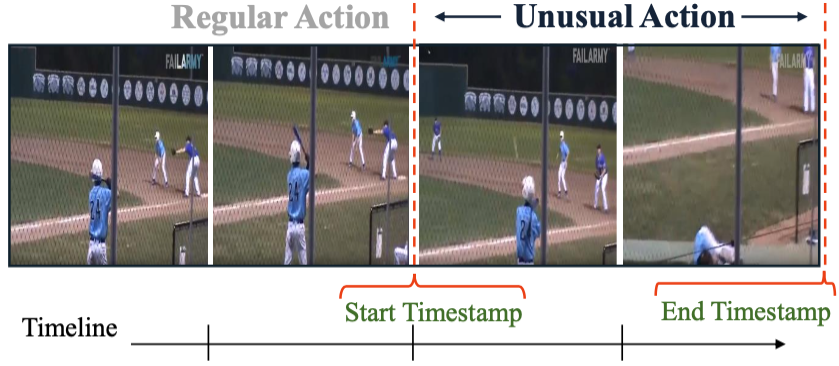
UAL-Bench: The First Comprehensive Unusual Activity Localization Benchmark
Hasnat Md Abdullah, Tian Liu, Kangda Wei, Shu Kong, Ruihong Huang
[WACV 2025]
arxiv /
poster /
code
We compile the first Unusual Activities Localization benchmark and propose VLM-LLM framework to improve multimodal
models for better video understanding.
|
Cyber-Physical Systems
|
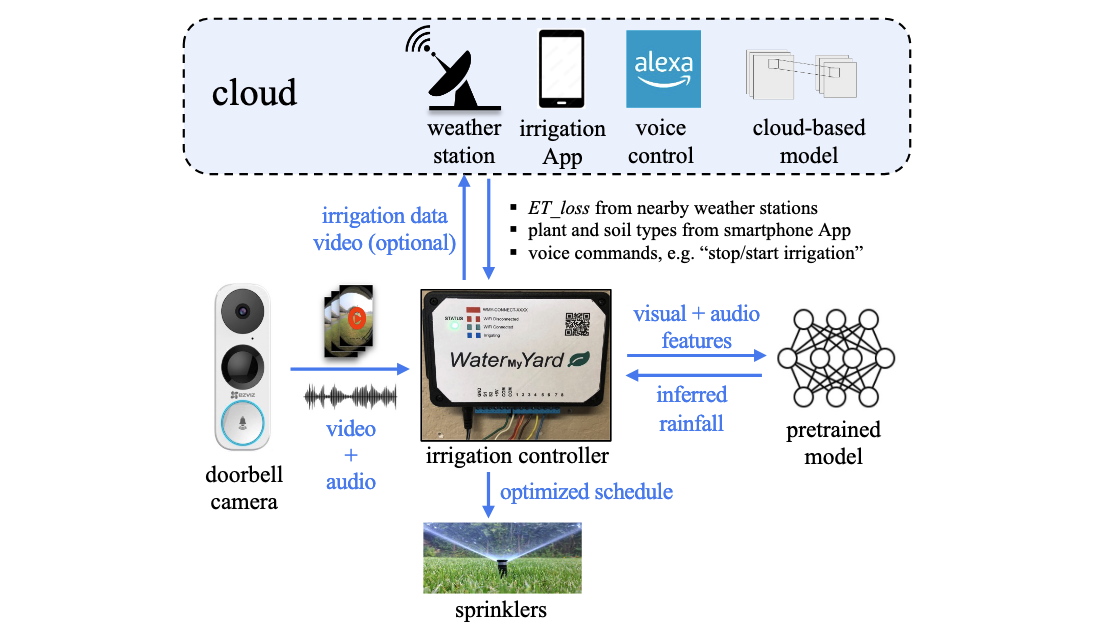
Robust Rainfall Estimation with Multimodal Sensing for Precision Residential
Irrigation
Tian Liu, Liuyi Jin, Radu Stoleru, Amran Haroon, Charles Swanson, Kexin Feng
[ACM Transactions on Sensor Networks (TOSN) 2025]
paper /
code
We developed low-cost, robust, privacy-preserving rainfall sensing system using multimodal data (visual recordings and audios from doorbell cameras).
|
|
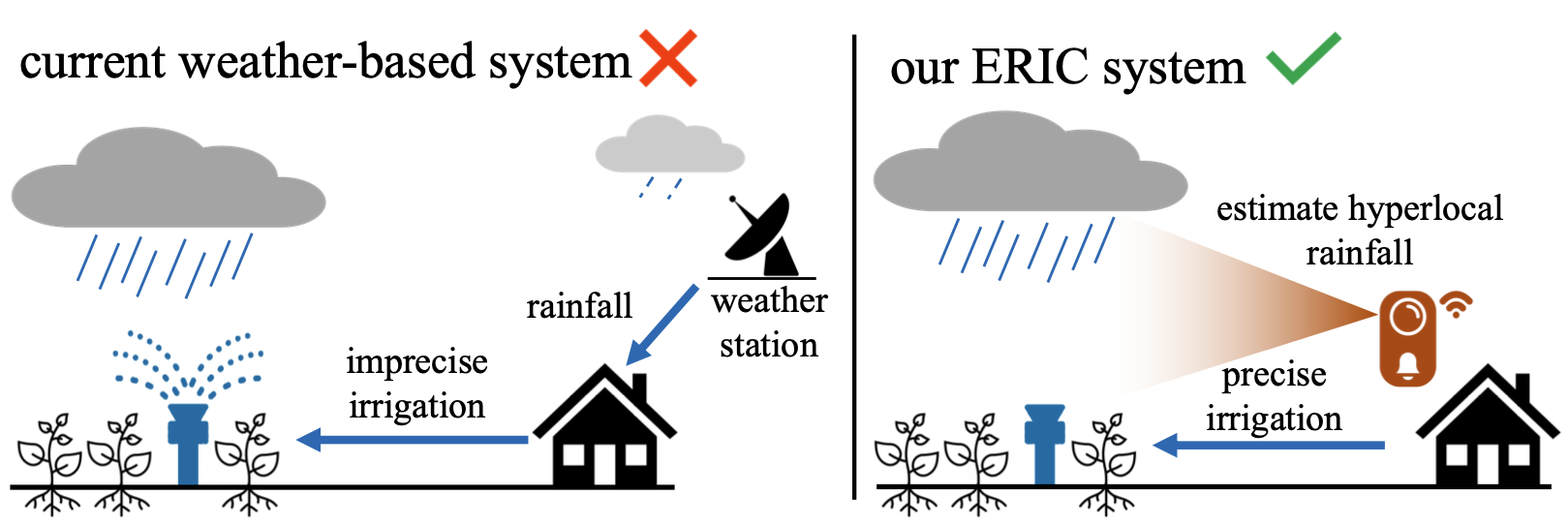
ERIC: Estimating Rainfall with Commodity Doorbell Camera for Precision Residential Irrigation
Tian Liu, Liuyi Jin, Radu Stoleru, Amran Haroon, Charles Swanson, Kexin Feng
[ACM BuildSys 2024]
Best paper award /
TPC praise
paper /
arxiv /
video presentation /
slides /
code /
TAMU CSE Media Coverage
Texas A&M Engineering News /
ASEE First Bell's newsletter
We develop efficient vision system to estimate hyperlocal rainfall from doorbell camera for precision residential irrigation,
saving > 9,000 gallons of water/month.
|
|
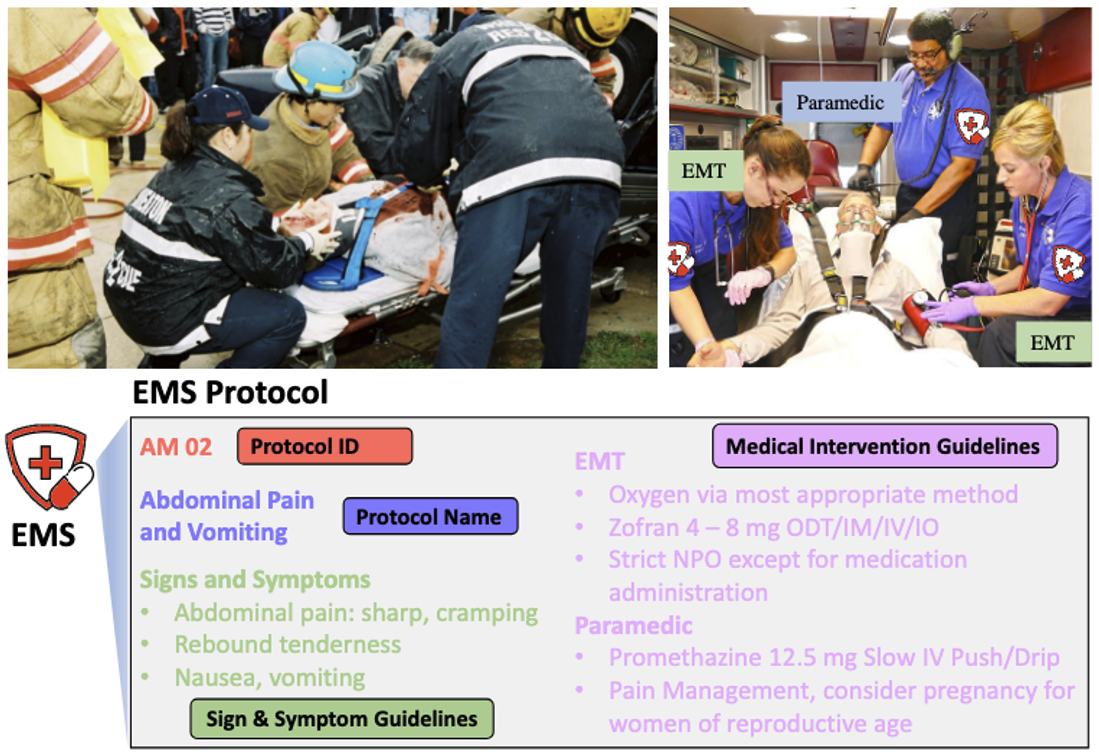
EMSAssist: An End-to-End Mobile Voice Assistant at the Edge for
Emergency Medical Services
Liuyi Jin, Tian Liu, Amran Haroon, Radu Stoleru, Michael Middleton, Ziwei Zhu, Theodora Chaspari
[ACM MobiSys 2023]
paper /
workshop paper /
presentation /
slides /
app demo /
code
We build the first end-to-end mobile voice assistant system to assist Emergency Medical Technicians in selecting proper protocols for critical medical intervention.
|
AI for Science
|
Safe Reinforcement Learning with Contextual Information: Theory and Application to Comorbidity Management
Junyu Cao*, Esmaeil Keyvanshokooh*, Tian Liu
preprint /
code
We develop a safe RL algorithm for contextual-based personalized medicine,
achieveing superior regret than prior arts with zero safety violation.
|
|
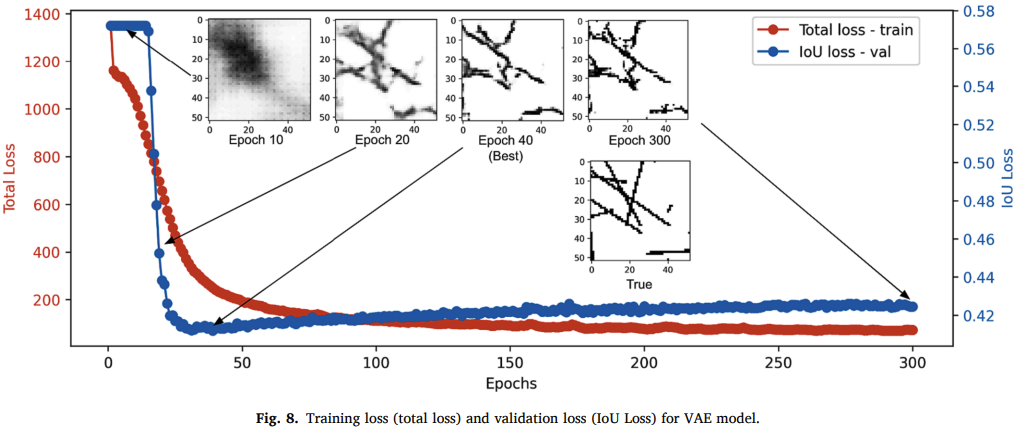
A Machine Learning-based Hybrid Model for Fracture Parameterization and
Distribution Prediction in Unconventional Reservoirs
Tian Liu, Ruxin Zhang
[Journal of Computers and Geotechnics 2024]
paper
We develop Variational Autoencoder (VAE) model for fracture parameterization
and distribution prediction using reservoir production data.
|
|
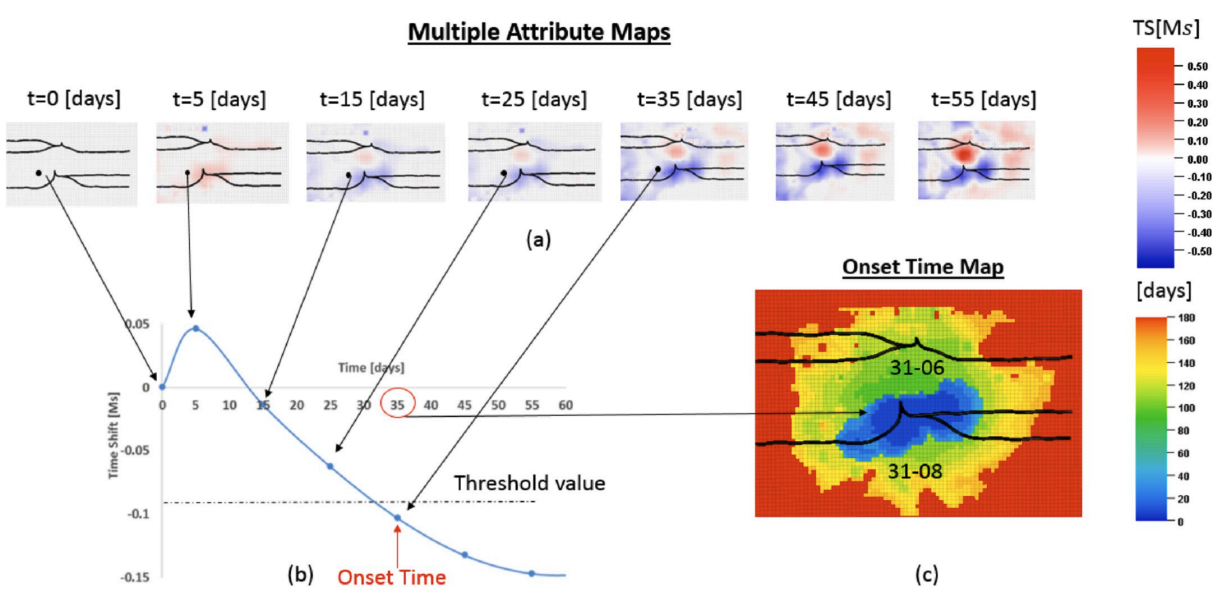
Integration of Time-lapse Seismic Data using the Onset Time Approach: the Impact of Seismic Survey Frequency
Tian Liu, Hongquan Chen, Gill Hetz, Akhil Datta-Gupta
[Journal of Petroleum Science and Engineering 2020]
1st Place of TAMU Student Paper Contest /
3rd Place of International Championship
JPSE journal paper /
ATCE paper
We develop a feature extraction method for efficient integration of massive 4D seismic data, achieveing 2x error reduction and 6x speedup.
|
Workshop Papers/Presentations
(* denotes equal contribution)
- T. Liu, H. Zhang, S. Parashar, S. Kong. "Few-Shot Recognition via Stage-Wise Retrieval-Augmented Finetuning." CVPR 2025 Workshop on Computer Vision in the Wild. Nashville, U.S, June 2025.
- T. Liu, H. Zhang, S. Parashar, S. Kong. "Few-Shot Recognition via Stage-Wise Retrieval-Augmented Finetuning." CVPR 2025 Workshop on Fine-Grained Visual Categorization. Nashville, U.S, June 2025.
- Y. Yang*, T. Liu*, S. J. Lee, C.-Y. Liao, H. Shao, F. Pasquel, M. B. Weber, E. Keyvanshokooh,
G.-G. P. Garcia. "Development and Fairness Evaluation of CVD Risk Prediction Models for
Patients with Type-2 Diabetes." Society for Medical Decision Making Annual Meeting, Boston,
MA, October 2024. Poster
- Y. Yang*, T. Liu*, S. J. Lee, C.-Y. Liao, H. Shao, F. Pasquel, M. B. Weber, E. Keyvanshokooh,
G.-G. P. Garcia. "Survival Modeling for CVD Risk Estimation Among a Diverse Cohort with
Type-2 Diabetes." AI for Health Equity Symposium AIM-AHEAD Annual Meeting, Atlanta,
GA, August 2024.
- S. Parashar*, Z. Lin*, T. Liu*, X. Dong, Y. Li, D. Ramanan,
J. Caverlee, and S. Kong, "The Neglected Tails in Vision-Language Models."
ICML 2024 Workshop on Data-centric Machine Learning Research (DMLR):
Datasets for Foundation Models, Vienna, Austria, July 2024.
- L. Jin, T. Liu, A. Haroon, R. Stoleru, M. Middleton, Z. Zhu,
T. Chaspari, "Demo: EMSAssist -- An End-to-End Mobile Voice Assistant at the Edge for
Emergency Medical Services." The 21st IEEE International Conference on Mobile Systems, Applications
and Services (MobiSys), 2023, Helsinki, Finland, June 2023.
Teaching Assistance
- CSCE670: Information Storage and Retrieval, Spring 2025
- CSCE606: Software Engineering, Fall 2023, Fall 2025
- CSCE313: Introduction to Computer Systems, Summer 2023
- CSCE110: Python Programming I, Summer 2023
Professional Services
- Coordinator of AutoAnnotation Expert Workshop at CVPR'26
- Coordinator of Open World Vision Workshop at CVPR'24, CVPR'25, CVPR'26
- Conference Reviewer for CVPR'26, ECCV'26, SIGKDD'26
- Conference Reviewer for WACV'25, ICLR'25 FM-Wild Workshop, ICCV'25, NeurIPS'25
- Journal Reviewer for Pattern Recognition, Internet of Things, Applied Thermal Engineering, Geoenergy Science and Enginerring, SPE Journal
Selected Awards
- TAMU CSE Department Travel Grant, 2025
- ACM BuildSys, Best Paper Award (1 out of 89 submissions), 2024
- TAMU CSE Department Travel Grant, 2024
- TAMU CSE Department Graduate Teaching Assistant Excellence Award (1 each year), 2024
- 1st place of SPE Student Paper Contest in TAMU, 1st place of Gulf Coast Region, 3rd place of International Championship, 2018
- 2nd place of SPE Petrobowl Knowledge Contest in North American Region, 2017
- 1st place of SPE Petrobowl Knowledge Contest in Asia-Pacific Region, 2015
- Dean's Award (4 out of 296), CUPB, 2014
- National Scholarship (top 1%), Ministry of Education of China, 2012
|